









When manipulating an object, existing text-to-image diffusion models often ignore the shape of the object and generate content that is incorrectly scaled, cut off, or replaced with background content. We propose a training-free method, Shape-Guided Diffusion, that modifies pretrained diffusion models to be sensitive to shape input specified by a user or automatically inferred from text. We use a novel Inside-Outside Attention mechanism during the inversion and generation process to apply this shape constraint to the cross- and self-attention maps. Our mechanism designates which spatial region is the object (inside) vs. background (outside) then associates edits specified by text prompts to the correct region. We demonstrate the efficacy of our method on the shape-guided editing task, where the model must replace an object according to a text prompt and object mask. We curate a new ShapePrompts benchmark derived from MS-COCO and achieve SOTA results in shape faithfulness without a degradation in text alignment or image realism according to both automatic metrics and annotator ratings.
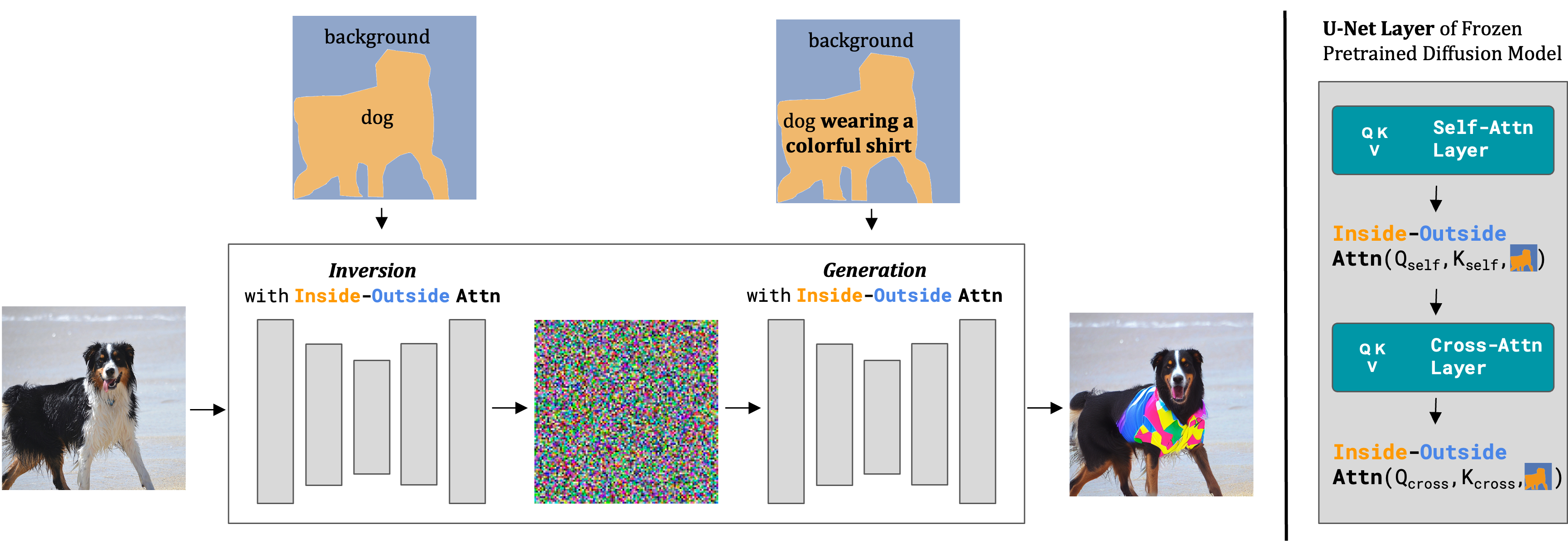
Our method takes a real image, source prompt ("dog"), edit prompt ("dog wearing a colorful shirt"), as well as an optional object mask (inferred from the source prompt if not provided), and outputs an edited image. Left: we modify a frozen pretrained text-to-image diffusion model during both the inversion and generation processes. Right: we show a detailed view of one layer in the U-Net, where Inside-Outside Attention constrains the self- and cross-attention maps according to the mask.
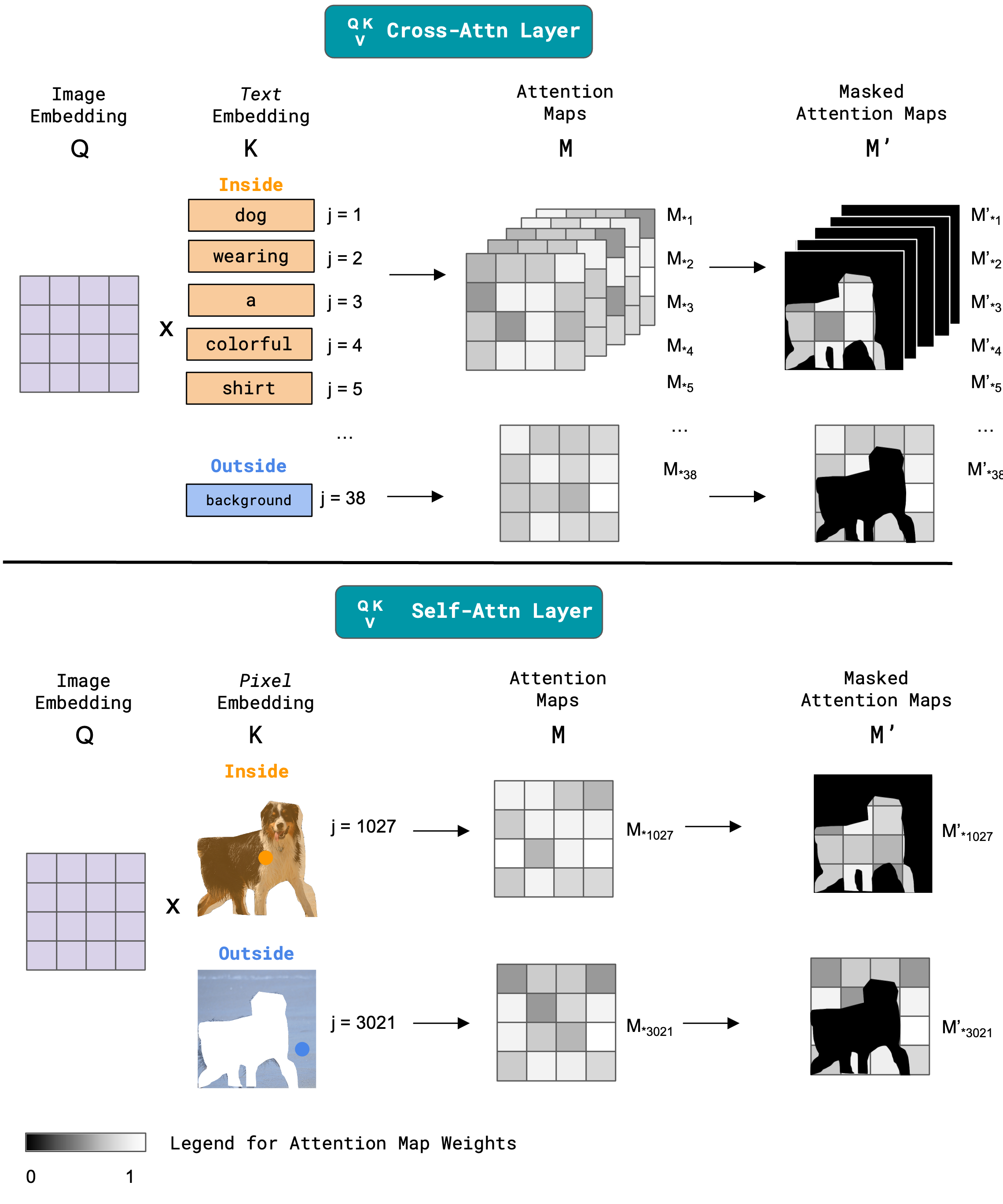
In our Inside-Outside Attention mechanism, we modify the attention maps in both the cross-attention and self-attention layers. In the cross-attention layer depending on whether the text embedding refers to the inside or outside the object, we constrain the attention map M according to the object mask or the inverted object mask to produce M'. In the self-attention layer we perform a similar operation on the inside and outside pixel embeddings.
Inter-Class Edits. Our method can perform both intra- and inter-class edits to the same object.

Background Edits. Our method is not only able to edit objects but also backgrounds.

Simultaneous Inside-Outside Edits. Since our method allows us to localize and separate the editing of the object and background, we can simultaneously edit both with two different prompts. This property allows us to maintain the relation of the object with the scene.

@inproceedings{park2024shape,
author = {Dong Huk Park* and Grace Luo* and Clayton Toste and Samaneh Azadi and Xihui Liu and Maka Karalashvili and Anna Rohrbach and Trevor Darrell},
title = {Shape-Guided Diffusion with Inside-Outside Attention},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
year = {2024},
}
 Shape-Guided Diffusion
Shape-Guided Diffusion 